

Mensch gegen Maschine: unser Praxistest mit KI-Agenten.
Während Du vielleicht noch überlegst, wie KI sinnvoll in Deinen Arbeitsalltag passt, baut Deine Konkurrenz vielleicht schon neue „Teammitglieder“ auf: autonome KI-Agenten. Und hat damit die „KI-Nase“ vorn.
Denn ja – KI-Agenten sind gerade der neue „heiße Scheiß“ der KI-Welt.
Sie können recherchieren, planen, vergleichen, klicken, einkaufen, analysieren und am besten gleich noch die PowerPoint fertig machen. Kurz gesagt: weniger selbst arbeiten, mehr delegieren. Zumindest in der Theorie.
Der Hype wächst gerade deutlich. Laut Gartner (1) sollen bis 2028 rund ein Drittel aller Enterprise-Softwarelösungen agentische KI enthalten. Außerdem könnten dann bereits 15 % aller alltäglichen Arbeitsentscheidungen autonom von KI getroffen werden – Marketing ausdrücklich eingeschlossen.
Fast jede große KI-Plattform baut inzwischen eigene Agenten: OpenAI testet Shopping-Agenten in ChatGPT. Perplexity hat Comet und Computer gestartet. Google entwickelt agentische Funktionen für Gemini. Microsoft integriert immer mehr autonome Assistenten in Copilot.
Der neue KI-Hype: Jede Plattform baut Agenten

Und plötzlich geht es nicht mehr nur um Content-Erstellung. Denn KI-Agenten können und werden selbstständig handeln.
Das Thema ist inzwischen so groß, dass sogar das TIME Magazine „AI Shopping Agents“ als einen der wichtigsten KI-Trends für 2026 bezeichnet (2).
KI-Agenten gelten als einer der wichtigsten KI-Trends für 2026

Kein Wunder also, dass wir bei KIRevolution von Kundinnen, Kunden und Marketingteams gerade viel gefragt werden: Was genau sind KI-Agenten? Brauchen wir das schon? Welches Tool funktioniert? Was kostet das?
Unsere Antwort darauf war erstmal: Langsam.
Denn es gilt: Nur weil ein KI-Agent theoretisch alles kann, heißt das noch lange nicht, dass er es auch sinnvoll tut.
Also wollten wir es genauer testen: Wie weit sind KI-Agenten?
Für diesen Praxistest haben wir einen Use Case aus dem Alltag einer Werbeagentur ausgewählt, also eine Aufgabe, die normalerweise von einem Menschen übernommen wird. Anschließend haben wir im Team bei KIRevolution verschiedene KI-Agenten gegeneinander antreten lassen.
Der kleine Wettbewerb dahinter: Wer arbeitet zuverlässiger? Mensch oder Maschine? Und wie nah sind wir schon an einem digitalen James Bond, der komplexe Aufgaben wirklich eigenständig übernimmt? Und das möglichst, anders als im Film, ohne rund um sich rumzuschießen.
Unsere Ergebnisse schauen wir uns jetzt an.
Kurz zur Einordnung: Das ist ein KI-Agent
Wir unterscheiden generative KI und agentische KI. KI-Agenten sind smarte Software-Assistenten, die nicht nur antworten, sondern eigenständig Aufgaben erledigen. Also eher digitale Mitarbeitende als klassische Chatbots.
Du gibst dem Agenten ein Ziel. Und das Tool plant anschließend selbstständig die notwendigen Schritte. Zum Beispiel:
- „Sortiere meine E-Mails nach Priorität, beantworte einfache Anfragen automatisch und markiere alle wichtigen Kundenanfragen für heute.“
- Der KI-Agent analysiert dann Deine E-Mails, priorisiert Inhalte, erkennt wiederkehrende Aufgaben und entscheidet, welche Aktionen notwendig sind – schickt für Dich also auch die E-Mails raus.
- Das Besondere: KI-Agenten können aktiv mit Tools und Programmen arbeiten. Sie durchsuchen Informationen, öffnen Anwendungen, organisieren Daten oder führen Aufgaben teilweise eigenständig aus.
Damit verändert sich die Rolle von KI grundlegend.
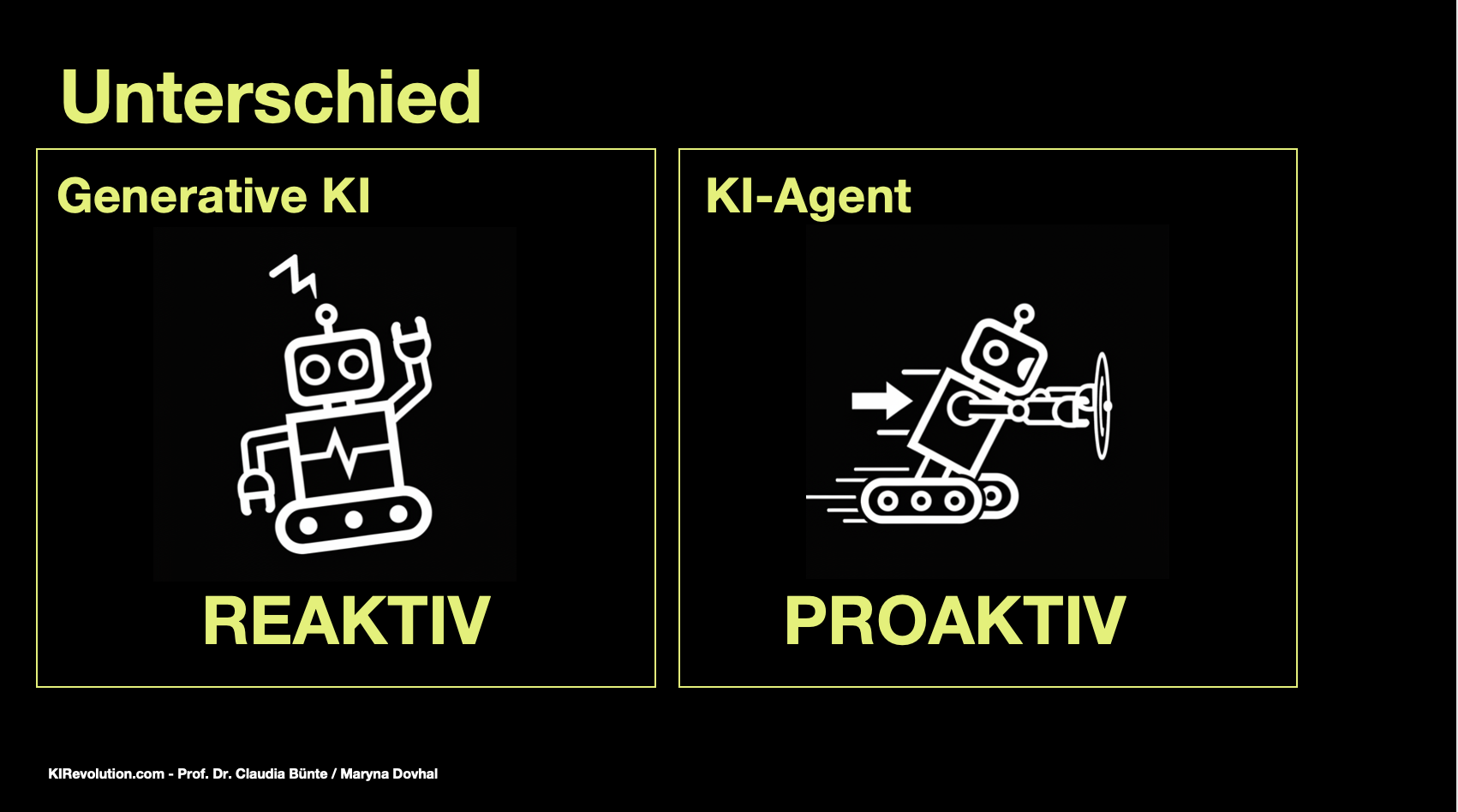
Generative KI wie ChatGPT oder Perplexity unterstützt Dich bisher bei einzelnen Aufgaben: Texte schreiben, Bilder erzeugen, Ideen entwickeln. Das Tool wartet auf Deinen Prompt, Du gibst den Befehl, das Tool erstellt den Inhalt und „legt sich wieder hin“. KI-Agenten dagegen sollen komplette Arbeitsprozesse übernehmen. Generative KIs sind reaktiv, agentische KIs sind proaktiv.
Vergleich: Generative KI vs. KI-Agenten
So haben wir bei KIRevolution getestet
Für den Praxistest wollten wir einen echten, zeitaufwendigen Prozess aus dem Agenturalltag testen. Und herausfinden: Kann ein KI-Agent diese Aufgabe sinnvoll übernehmen oder zumindest deutlich beschleunigen?
Der Use Case:
Eine Werbeagentur sucht regelmäßig nach öffentlichen Ausschreibungen, auf die sie sich bewerben kann. Dafür müssen verschiedene Ausschreibungsplattformen durchsucht, passende Keywords getestet, relevante Projekte bewertet und die Ergebnisse anschließend für die Geschäftsführung aufbereitet werden.
Klassischerweise bedeutet das: viel Recherche, viele Tabs und viel Aufwand – bis zu vier Stunden manueller Recherche pro Woche durch einen Mitarbeitenden.
Die KI-Tools:
Für den Test habe wir zwei KI-Agenten ausgewählt:
Der Hintergrund: Beide Tools versprechen eigenständiges Recherchieren, Strukturieren und Bearbeiten komplexerer Aufgaben – also genau das, was bei Ausschreibungssuchen relevant ist.
Die Kosten:
Der Test lief mit den regulären Bezahlversionen der Tools:
- Manus AI: 20 US-Dollar pro Monat
- Perplexity Pro mit Comet: 20 US-Dollar pro Monat
Gesamtkosten des Praxistests: rund 40 US-Dollar.
Der Ablauf:
Der Test lief über einen Monat.
Jeden Montag haben die KI-Agenten eigenständig nach passenden Ausschreibungen gesucht. Parallel dazu hat ein Mitarbeitender der Agentur dieselbe Aufgabe weiterhin manuell durchgeführt.
Verglichen haben wir dann: Zeitaufwand, Qualität der Ergebnisse, Anzahl relevanter Treffer, Nachbearbeitungsaufwand, und die praktische Nutzbarkeit im Arbeitsalltag.
Außerdem haben wir die Prompts im Verlauf des Tests immer weiter angepasst und optimiert.
Denn auch das wurde schnell deutlich: Das Problem sitzt meistens VOR dem Rechner. Wir wussten am Anfang noch nicht so gut, wie man KI-Agenten richtig gut aufsetzt, also promptet.
Unsere Ergebnisse bei KRevolution
Zwei grundsätzliche Learnings zum Aufsetzen von KI-Agenten vorneweg:
Der Prompt ist richtig wichtig
Bei KI-Agenten entscheidet der Auftrag, also der Prompt, massiv über die Qualität der Ergebnisse. Ein schneller Einzeiler reicht hier auf keinen Fall aus.
KI-Agenten brauchen:
- klare Ziele
- saubere Rahmenbedingungen
- klare Kriterien, nach denen der KI-Agent entscheidet, was relevant ist
- Prioritäten
- möglichst konkrete Entscheidungslogiken
- klar definierte Output-Regeln
Im Grunde genauso, wie Du eine komplexere Aufgabe an Mitarbeitende delegieren würdest.
Englisch ist besser als Deutsch
Die KI-Agenten arbeiteten mit englischen Prompts deutlich stabiler als mit deutschen Anweisungen. Gerade bei komplexeren Aufgaben, mehreren Regeln und strukturierten Prozessen waren die Ergebnisse auf Englisch konsistenter und nachvollziehbarer.
Deshalb sahen unsere besten Prompts ungefähr so aus – bewusst generalisiert und mit Platzhaltern. Dann kannst Du sie für Dich kopieren:
Role: You are a tender scouting agent for [AGENCY NAME], a full-service communication and advertising agency in Germany. Goal: Find new or still-open public tenders relevant to [AGENCY NAME] services and summarize them in structured form. Focus on tenders which match the agency’s strengths in: [SERVICE AREAS], and where the agency has strong reference projects.
-
1. TIME & DEADLINE FILTER
Consider only tenders whose submission deadline is more than [X DAYS] from today. If the deadline is shorter or unclear, do not include it.
2. SOURCES
Use the portals listed here as primary sources. Search across open public procurement portals such as: [LIST OF PORTALS WITH LINKS]
3. SEARCH FILTERS
On each portal, use combinations of these terms in the search box and filters: German: [RELEVANT KEYWORDS, as Kommunikation, Kommunikationsagentur, Kommunikationsleistungen, Kampagne, Marketing, Marketingagentur, Werbung, Werbeagentur, Öffentlichkeitsarbeit, PR]. English (if helpful on a portal): [RELEVANT KEYWORDS, as communication services, communication agency, marketing services, advertising services, PR campaigns]. When the portal offers filters or advanced search, combine these keywords with categories related to “Marketing”, “Werbung”, “Kommunikation”, “PR”, “Beratung” or similar options. If a portal shows only partial information behind a login, collect all visible metadata and search for an open version of the tender via web search.
4. RELEVANCE FILTER
The main scope is one or more of: [SERVICE AREAS, as: Communication services, PR, public affairs, media relations; Strategic consulting and workshops; Development and implementation of communication or marketing campaigns]. The agency has strong references in: [INDUSTRIES / TOPICS] Additional filters:
-
-
-
Project size should fit an agency of [AGENCY SIZE / REVENUE].
-
Minimum project volume: [AMOUNT].
-
Deadline must be at least [X DAYS] from today.
-
-
-
-
-
-
-
-
Client + location
-
Category
-
Short project description
-
Deadline
-
Estimated project volume
-
Exclusion criteria
-
Tender portal link
-
-
-
-
5. OUTPUT FORMAT
If NO suitable tenders are found: Output exactly: No new suitable tenders this week. Otherwise: Create a Markdown table. Highlight particularly suitable tenders in bold.
Manus AI im Praxistest
Manus AI ist ein KI-Agent, der Recherche, Planung, Browser-Nutzung und strukturierte Workflows in einem System kombiniert.
Besonders spannend für unseren Test war die Möglichkeit, wiederkehrende Aufgaben automatisiert auszuführen. Genau das passte gut zu unserem Ausschreibungs-Use-Case.
So funktioniert die Einrichtung
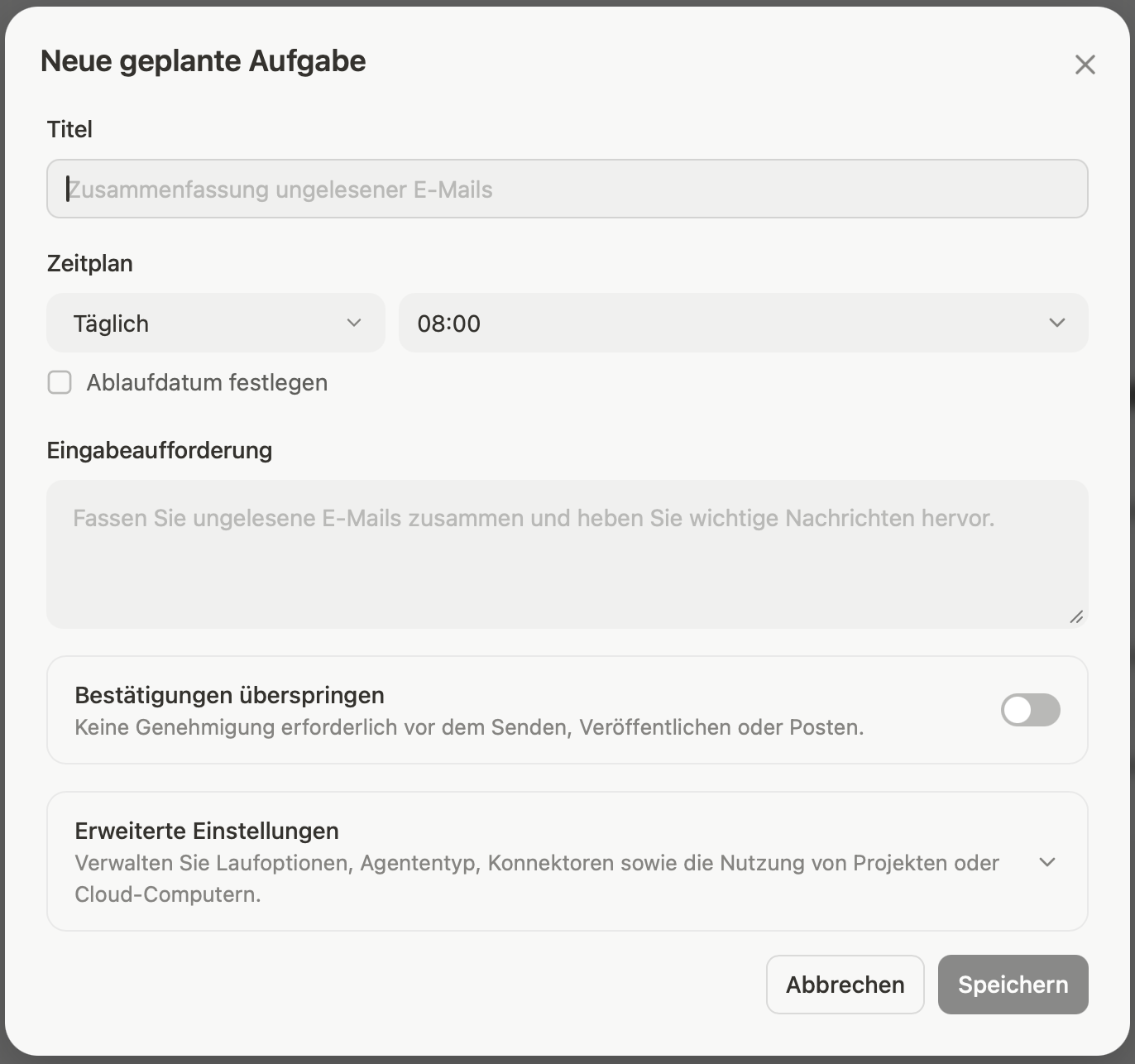
Manus bietet dafür eine Funktion für sogenannte „Scheduled Tasks“. Die Einrichtung war vergleichsweise einfach:
- Aufgabe definieren
- Prompt hinterlegen
- Zeitplan festlegen
- automatische Ausführung starten
Alternativ kann man die Aufgabe auch direkt im Chat beschreiben. Manus erstellt daraus anschließend einen automatisierten Workflow.
In unserem Fall lief die Ausschreibungsrecherche jeden Montag automatisiert an. Der Agent durchsuchte verschiedene Vergabeplattformen, filterte Ergebnisse nach den definierten Kriterien und bereitete die Resultate strukturiert auf.
So richtest Du automatisierte Aufgaben in Manus AI ein
Das hat gut funktioniert
Besonders positiv war die Recherchetiefe. Manus arbeitete sich sichtbar durch unterschiedliche Quellen und lieferte oft eine große Anzahl potenziell relevanter Ausschreibungen. Auch strukturierte Ergebnislisten funktionierten zuverlässig. Gut war außerdem:
- wiederkehrende Automatisierung
- strukturierte Rechercheprozesse
- Zusammenfassung komplexerer Informationen
- Verarbeitung längerer Prompts mit vielen Regeln und Filtern
Gerade für zeitintensive Rechercheaufgaben steckt hier aus unserer Sicht viel Potenzial.
Aber, es gab Grenzen
Vor allem waren nicht alle gefundenen Ausschreibungen tatsächlich relevant. Teilweise fehlte der fachliche Kontext, um Projekte realistisch einzuordnen. Dadurch entstand zusätzlicher manueller Prüfaufwand.
Außerdem wurde schnell klar: Der Agent arbeitet nicht vollständig autonom. Er braucht weiterhin Kontrolle, Nachsteuerung, Prompt-Optimierung, und regelmäßige Qualitätssicherung. Gerade längere Aufgabenketten wurden teilweise instabil:
- Ergebnisse blieben unvollständig
- Quellen waren nicht immer sauber nachvollziehbar
- manche Tasks brachen ab
- und größere Workflows wurden langsam
Hinzu kam das Credit-System. Im getesteten 40-Dollar-Tarif standen uns 8.000 Guthabenpunkte pro Monat plus 300 zusätzliche Credits pro Tag zur Verfügung. Bei unserem Use Case war das Kontingent allerdings bereits nach rund 15 Recherchedurchläufen inklusive Tests und Prompt-Optimierungen aufgebraucht. An diesem Punkt haben wir den Praxistest bewusst beendet und keine weiteren Credits nachgekauft.
Ein weiterer Punkt: Manus konnte in unserem Test zwar Informationen recherchieren und strukturieren, aber keine vollständigen E-Mail-Prozesse automatisiert übernehmen.
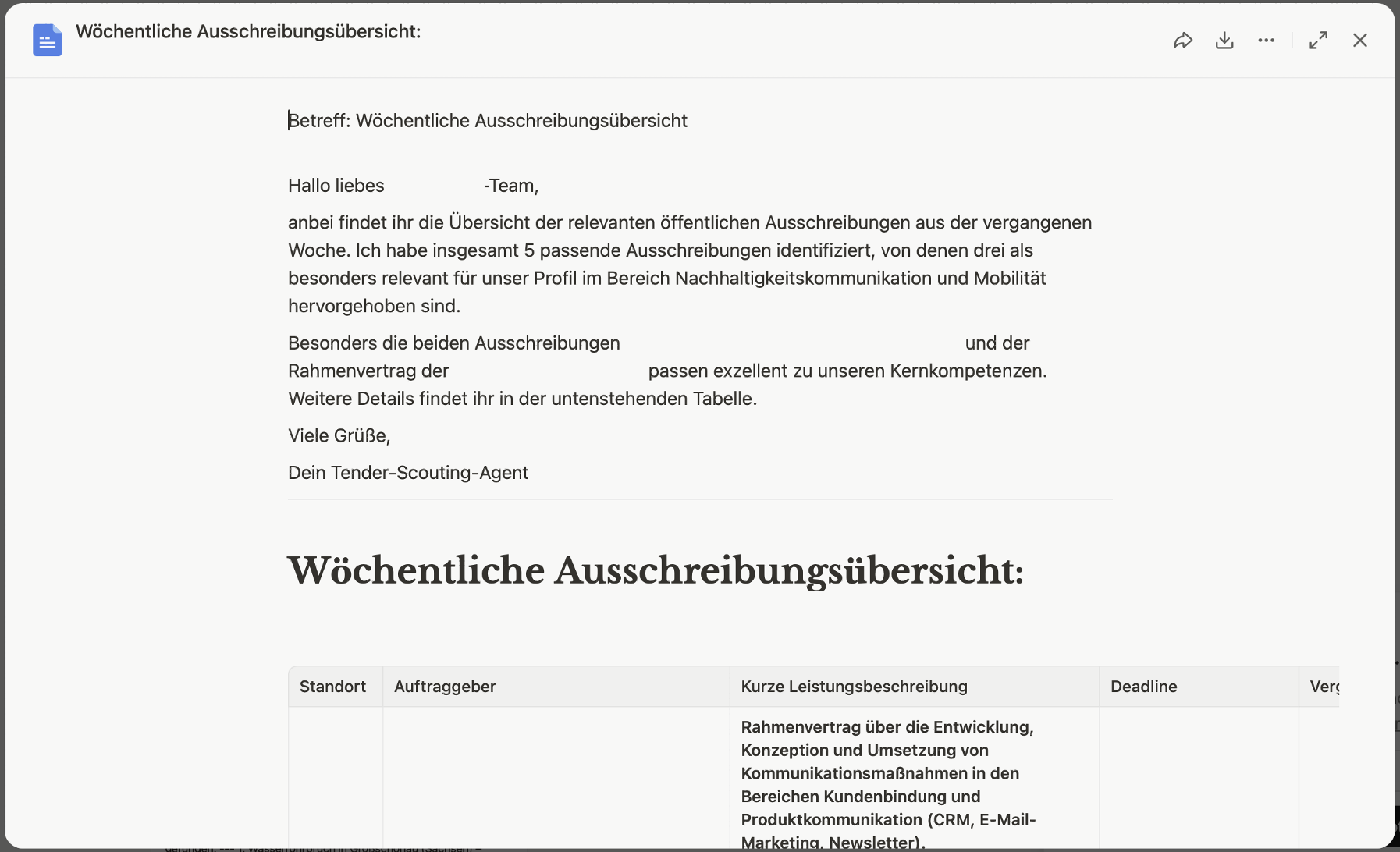
So sahen die Recherche-Ergebnisse des Manus-Agenten aus
Comet AI im Praxistest
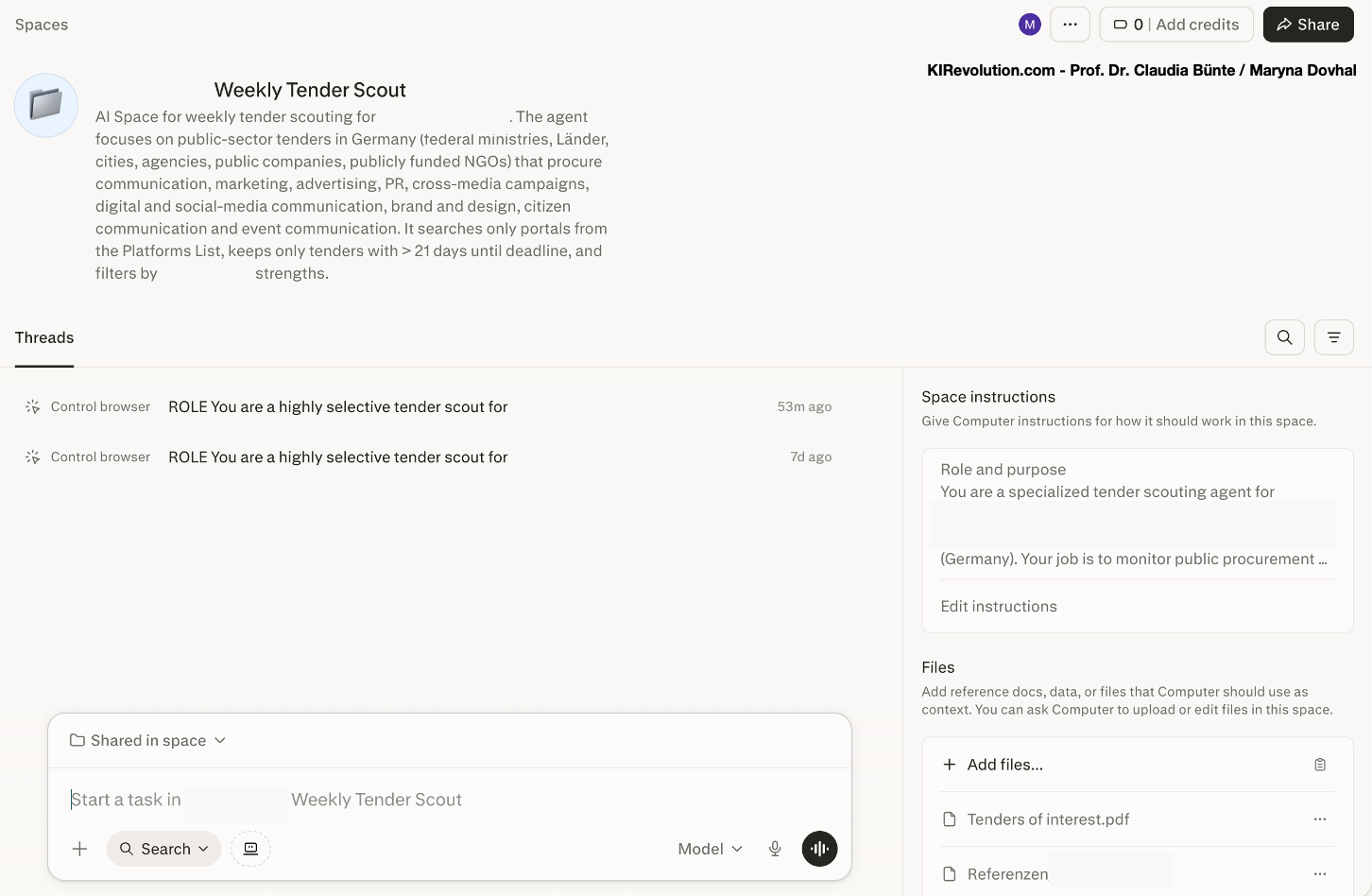
Comet ist der KI-Agent von Perplexity und kombiniert Web-Recherche mit agentischen Funktionen. Für unseren Test war vor allem die sogenannte Spaces-Funktion spannend.
Ein Space funktioniert wie ein personalisierter Arbeitsbereich für einen bestimmten Use Case. Dort lassen sich:
- individuelle Instructions hinterlegen
- Dokumente und Links hochladen
- wiederkehrende Aufgaben automatisieren
- Ergebnisse speichern
- und zusätzliche Skills definieren
Dadurch entsteht eine Art Gedächtnis für den Agenten. Frühere Aufgaben und Informationen bleiben erhalten und können für neue Recherchen genutzt werden.
Für meinen Ausschreibungs-Use-Case klang das erst mal ziemlich ideal.
Comet Spaces: KI-Arbeitsbereiche für wiederkehrende Aufgaben
Das hat gut funktioniert
Besonders stark war die Personalisierung. Wir konnten dem Agenten Informationen zur Agentur, relevante Ausschreibungsportale, Referenzprojekte, Entscheidungsregel und konkrete Ausschlusskriterien mitgeben.
Zusätzlich lassen sich – ähnlich wie bei Manus – „Scheduled Tasks“ einrichten. Ein großer Vorteil: Nach jeder automatisierten Recherche schickte Comet automatisch eine E-Mail mit einer Kurz-Zusammenfassung und Link zu den vollständigen Ergebnissen.
Gerade die Kombination aus Memory, Dokumenten, personalisierten Instructions, automatisierten Tasks, und Benachrichtigungen wirkte im Test zunächst deutlich ausgereifter als bei Manus AI.
Das hat nicht funktioniert
In der Praxis zeigte sich allerdings schnell ein Problem: Die automatisierten Tasks lieferten häufig zu wenige oder gar keine relevanten Ausschreibungen.
Unser Eindruck im Team von KIRevolution: Der Agent war durch die vielen Vorgaben und Filter möglicherweise zu stark eingeschränkt und suchte nur nach „perfekten Treffern“. Gleichzeitig hatten wir das Gefühl, dass die automatisierte Recherche insgesamt weniger tief arbeitete als erwartet.
Comet AI schickte die Recherche-Ergebnisse automatisch per E-Mail

Unser Workaround
Interessant wurde es, als wir denselben Prompt nicht mehr automatisiert im Space genutzt haben, sondern manuell direkt im Comet-Assistenten. Und plötzlich wurden die Ergebnisse deutlich besser. Die Recherche war tiefer, relevanter, strukturierte und insgesamt qualitativ stärker als bei Manus AI.
Der Nachteil: Die Aufgabe musste jedes Mal manuell gestartet werden. Damit ging der eigentliche Automatisierungs-Vorteil wieder verloren.
Genau hier zeigte sich im Test eine der aktuellen Grenzen vieler KI-Agenten: Automatisierung klingt oft weiter, als sie im Alltag tatsächlich ist.
Comet AI: So findest Du Spaces, Scheduled Tasks und den Assistent
Unsere Learnings
Nach mehreren Wochen Test wurde vor allem eines klar: KI-Agenten funktionieren aktuell am besten nicht als vollständiger Ersatz für Mitarbeitende, sondern als operative Assistenz.
Diese Punkte waren für uns besonders wichtig:
- KI-Agenten benötigen ein klares Ziel – keine vagen Aufgabenstellungen. Je konkreter die Aufgabe, desto besser die Ergebnisse.
- Gute Prompts werden noch wichtiger. Besonders bei komplexeren Prozessen helfen klare Regeln, Prioritäten und Entscheidungskriterien.
- Englisch funktionierte im Test stabiler als Deutsch. Gerade bei längeren Instructions und mehrstufigen Aufgaben waren die Ergebnisse konsistenter.
- KI-Agenten benötigen Kontrolle. Auch gute Ergebnisse müssen geprüft werden, besonders bei Recherche, Priorisierung und Relevanzbewertung.
- Iteration ist entscheidend. Die Qualität wurde erst besser, nachdem die Prompts mehrfach angepasst und optimiert wurden.
- Mehr Kontext macht Agenten oft stärker, aber manchmal auch zu restriktiv. Zu viele Regeln können dazu führen, dass relevante Ergebnisse herausgefiltert werden.
Und zu „Mensch oder Maschine“ – wer war besser?
Dazu würden wir heute sagen: Eigentlich ist das die falsche Frage. Denn im Alltag geht es weniger um Konkurrenz als um Zusammenarbeit.
Die Agenten sind im Moment ganz OK operative Assistenten. Man muss sie briefen, festlegen, wie das Endprodukt aussehen soll, dann laufen lassen und dann wieder übernehmen und die Ergebnisse prüfen, oder optimieren oder selbst noch einmal recherchieren. Sie nehmen 80 % der Arbeit ab, aber eben nicht 100 %.
Fazit und strategischer Ausblick für Unternehmen
KI-Agenten sind keine Science-Fiction mehr. Aber sie sind aktuell auch noch keine vollständig autonomen digitalen Mitarbeitenden.
Unser klarer Favorit bei KIRevolution im Test war trotzdem Comet AI.
Die Ergebnisse waren insgesamt relevanter, die Recherche tiefer und die Bedienung einfacher als bei Manus AI. Die besten Ergebnisse entstanden, wenn wir den Prompt manuell starteten, also mit Mensch und KI-Agent im Zusammenspiel.
Genau darin liegt aus meiner Sicht aktuell der größte Mehrwert: Der Agent recherchiert, strukturiert und beschleunigt operative Arbeit + der Mensch bewertet, priorisiert und entscheidet.
Trotz aller Schwächen: Die Entwicklung geht extrem schnell. Viele Funktionen, die heute noch instabil oder halb automatisch wirken, könnten in wenigen Monaten deutlich besser funktionieren.
Denn die zentrale Frage ist nicht mehr: Kommen KI‑Agenten?
Sondern: Wie arbeiten Unternehmen und wir Menschen künftig sinnvoll mit ihnen zusammen?
Und genau dafür braucht es jetzt vor allem eines: experimentieren, testen, lernen. Und Mitarbeitende, die verstehen, wie man KI sinnvoll steuert.
KI-Agenten selbst testen und sinnvoll einsetzen
Wenn Du jetzt Lust bekommen hast, KI-Agenten selbst auszuprobieren: Genau dafür haben wir bei KIRevolution verschiedene Formate entwickelt, praxisnah und ohne unnötigen KI-Hype.
- Kostenlose KI-Lifehacks: Comet AI im Marketing-Alltag
In diesen kompakten Praxisvideos zeigen wir konkrete Anwendungen von KI-Agenten im Marketing-Alltag, inklusive einfacher Beispiele zum direkten Ausprobieren.
- KI-Masterclass vor Ort: KI-Agenten mit echten Use Cases trainieren
In unserer KI-Masterclass bei KIRevolution arbeiten wir gemeinsam mit realen Marketing-Szenarien und testen KI-Agenten direkt praktisch.Du lernst: wie KI-Agenten funktionieren, wie gute agentische Prompts aufgebaut werden, welche Aufgaben sich wirklich automatisieren lassen, und wie KI-Agenten sinnvoll mit anderen KI-Tools zusammenspielen. Natürlich immer mit Fokus auf Marketing, Kommunikation und praktische Anwendungen im Unternehmen.
- KI-Agenten als Teil von Inhouse-Schulungen
Viele Unternehmen stehen aktuell vor derselben Frage: Welche Rolle sollen KI-Agenten künftig im Team übernehmen? Deshalb integrieren wir das Thema inzwischen auch in unsere Inhouse-Schulungen – individuell angepasst an Prozesse, Teams und konkrete Anwendungsfälle im Unternehmen.
Interesse? Dann schreib mir einfach eine Mail an: claudia@kirevolution.com
Berlin, 18. Mai 2026
Prof. Dr. Claudia Bünte / Maryna Dovhal
Quellen:
- Gartner. (2025, June 25). Gartner predicts over 40% of agentic AI projects will be canceled by end of 2027. https://www.gartner.com/en/newsroom/press-releases/2025-06-25-gartner-predicts-over-40-percent-of-agentic-ai-projects-will-be-canceled-by-end-of-2027
- TIME. (2026, January 14). 5 predictions for AI in 2026. https://time.com/collections/davos-2026/7339222/ai-predictions-2026/






{kind=link}
{kind=link}