

Einleitung
Künstliche Intelligenz ist DAS Zukunftsthema des 21. Jahrhunderts mit massiven Auswirkungen auf die Wirtschaft. Dabei ist KI häufig eine Black Box. Nicht immer ist klar, wie die Algorithmen zu Entscheidungen kommen. Was ist, wenn diese Black Box diskriminiert? Ein Überblick über den Bias von KI, die Gründe dafür und mögliche Auswirkungen auf Wirtschaft und Ethik.
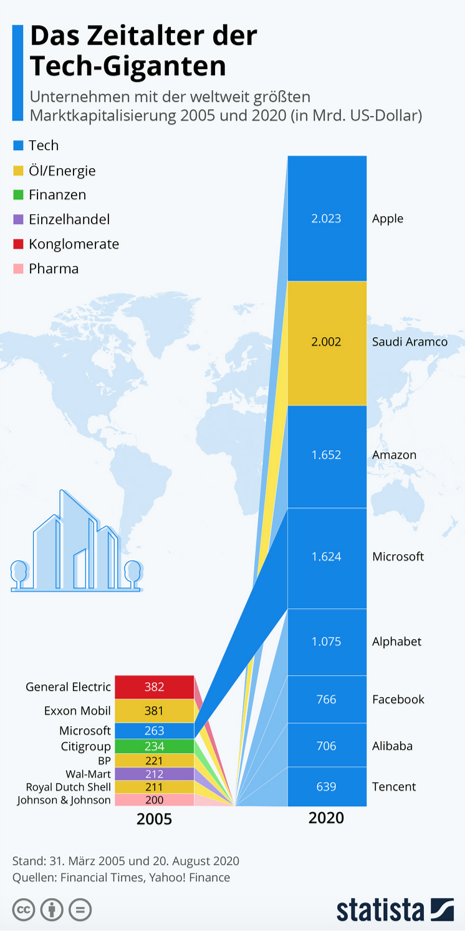
Künstliche Intelligenz ist in aller Munde, mit weit umspannenden Herausforderungen und Chancen für die Wirtschaft, die Politik, die Gesellschaft und für die Ethik. Expert*innen gehen davon aus, dass die Unternehmen und die Länder, die am besten mit KI arbeiten, weltweit führend sein werden. Das ist heute schon sichtbar: 2019 waren die Top 3 größten Unternehmen weltweit: Microsoft, Apple und Amazon.
Deren Geschäftsmodelle basieren größtenteils auf Software und KI (Quelle: PWC Global Top 100 (2019). 2008 waren die Top 3-Unternehmen noch Exxon Mobil, PetroChina und General Electrics – deren Geschäftsmodell auf fossilen Brennstoffen beruhte (Quelle: Financial Times Deutschland).
Künstliche Intelligenz wird heute schon in vielen Wirtschaftsbereichen eingesetzt, auch im Mittelstand – z.B. in der Produktion, der Lagerhaltung, im Marketing und im HR-Bereich. Große Anbieter wie Adobe, Microsoft, Amazon, Salesforce, Alibaba, Tencent und andere bieten ihren Kunden KI-basierte Lösungen und Softwaretools an.
Deren Aufbau bleibt dabei häufig für den Anwendenden eine sogenannte „Black Box“. Es ist vielfach unklar, WIE genau der Algorithmus auf die Empfehlungen und Lösungen kommt.
Aber wie neutral ist eine KI eigentlich, wenn diese z.B. Vorschläge erarbeitet, welche Bewerber*innen eingestellt werden und wer intern für Schulungen vorgeschlagen wird? Werden Fußgänger-*innen mit dunklerer Haut von selbs-tfahrenden Autos genauso erkannt wie solche mit heller Haut?
KI bei Diskriminierungen erwischt
Tatsächlich gibt es zahlreiche Studien, die feststellen, dass künstliche Intelligenz diskriminieren kann. Und das sehr breit, vor allem nach Geschlecht (Männer positiver als Frauen) und ethnischer Herkunft (hellerer Hauttyp positiver als dunklerer Hauttyp).
Zu einer möglichen Bevorzugung nach Alter finden sich dagegen weniger Belege. Entweder, weil hier weniger Diskriminierung vorkommt, oder, weil dieser Bereich für Forschende noch nicht so interessant ist wie Diskriminierungen nach Geschlecht und Hautfarbe. Die nachgewiesenen Diskriminierungen finden in allen wichtigen KI-Bereichen statt, so etwa in der Bilderkennung und in der Textverarbeitung.
Bilderkennung
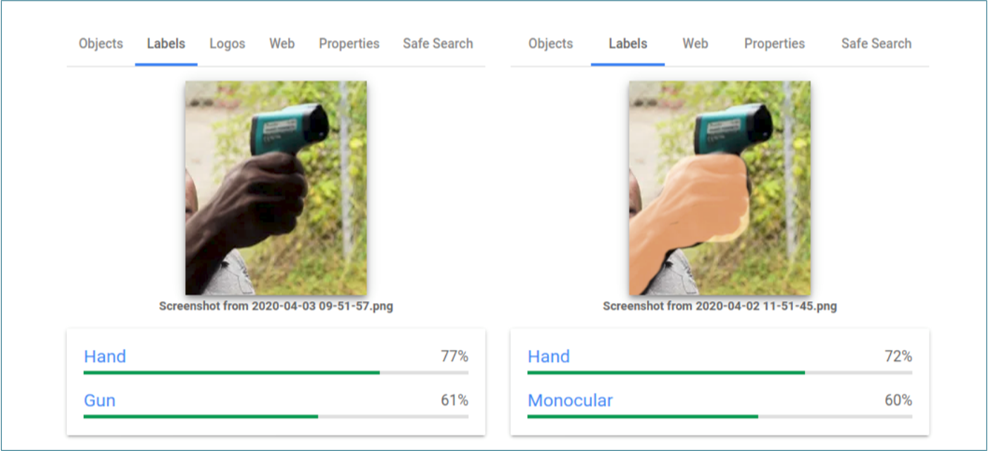
Google musste erst im April öffentlich lernen, dass ihre Vision Cloud dunkle Hauttypen offenbar negativer besetzt. Ein Foto das eine weiße Hand mit einem Corona-Fiebermessgerät zeigt, wurde von Google als „elektrisches Gerät“ erkannt, dasselbe Foto mit einer dunkelhäutigen Hand wurde als „Waffe“ gelabelt.
Die Forscherin Buolamwini untersuchte bereits 2015 IBM, Microsoft und Face++ bezüglich deren Fähigkeiten, Gesichter zu erkennen und stellte fest, dass alle drei Firmen besser darin waren, Männer zu erkennen als Frauen, und Menschen mit hellerem Hauttyp besser als Menschen mit dunklerem Hauttyp. Die schlechteste Gesichtserkennung zeigten alle drei Algorithmen bei dunkel-häutigen Frauen. (https://t1p.de/lxz8)
Und in Asien sind Gesichtserkennungs KIs deutlich besser und schneller darin, asiatische Menschen zu erkennen und beispielsweise ihr Alter korrekt zu schätzen als europäisch aussehende Menschen. Der Grund liegt auf der Hand: Die Trainingsdaten für KI von asiatischen Anbietern sind zum überwiegenden Teil asiatische Gesichter (Selbstversuch Prof. Bünte auf Innovationsreise China).
Texterkennung
Linzer Forscher zeigen aktuell, dass Ergebnisse von Suchmaschinen, die Deep Learning nutzen, besonders verzerrt in Bezug auf das Geschlecht sind. Bei Fragen wie etwa nach dem Einkommen einer Pflegekraft oder nach einem Synonym für „schön“ warfen die getesteten Suchmaschinen vor allem Antworten im Zusammenhang mit Frauen aus, Männer kamen erst weit hinten vor.

Umgekehrt lieferte etwa die Suche nach „CEO“, oder „Programmierer“ überwiegend männlich konnotierte Antworten. Der Grund für die besondere Verzerrung von Deep-Learning-Algorithmen sehen die Forschenden darin, dass diese potenteren Algorithmen nicht nur den Begriff an sich, sondern auch verwandte Begriffe suchen. Und da „Pflegekraft“ häufig im Zusammenhang mit „Oberschwester“ gebraucht wird, kommt der Algorithmus nach dem Gesetz der Wahrscheinlichkeit zum Schluss, „Pflegekraft“ müsse weiblich sein. (https://t1p.de/q3cv)
2018 verwarf Amazon sein von Machine Learning gestütztes Bewertungsstool, das das Unternehmen zur automatischen Auswahl von Bewerberinnen nutzen wollte. Der Grund: Der Algorithmus hatte sexistische Tendenzen und bewertete Männer grundsätzlich mit einer höheren Punktzahl als Frauen. Das Maschine-Learning-System habe sich dieses Fehlverhalten selbst beigebracht und das Attribut, männlich zu sein, sehr hoch gewichtet. Das System sollte Bewerber*innen auf einer Skala von eins bis fünf Sternen einsortieren. (https://t1p.de/79k5)
Auch eine aktuelle Studie der HTW Berlin untersuchte KI-Lösungen, die in Personalabteilungen automatisch Zeugnisse von Bewerber*innen analysiert. Geprüft wurden die Lösungen von Google Natural Language API, Amazon Web Service Comprehend, IBM Watson Natural Language Understanding und Microsoft Azure Cognitive Service.
Ziel war es, zu testen, ob Arbeitszeugnissätze bei einer Änderung des Geschlechts oder des Nachnamens des Proband*innen unterschiedlich bewertet werden. Die Formulierung „stets zu unserer vollsten Zufriedenheit“ steht z.B. eigentlich immer für die Note eins. Im Test stellte sich heraus, dass bei allen KI-Anbietern Zeugnisse von Männern positiver zusammengefasst wurden als die von Frauen, obwohl in den Zeugnissen immer vergleichbare Einschätzungen enthalten waren.
Keine der Lösungen war dagegen negativer gegenüber ausländisch klingenden Namen oder deutlich positiver gegenüber akademischen Titeln ein-gestellt. Die Forscher*innen um Prof. Dr. Katharina Simbeck raten deshalb auch dazu, „keine der getesteten Dienstleistungen in einem HR-Kontext zu nutzen, da alle vier die Notwendigkeit eines Fairnessbewusstseins vernachlässigen. Arbeitgeber, die diese Dienstleistungen integrieren, würden systematisch geschlechtsspezifische Prozesse mit ethischen Risiken einführen.“ (https://t1p.de/92rz)
Der Schaden für die Wirtschaft, wenn diese Bevorzugung bzw. Benachteiligung unbemerkt oder unbehoben bliebe, kann groß werden. Studien kommen regelmäßig zum Ergebnis, dass Unter-nehmen mit einer diversen Belegschaft nach Alter, Geschlecht und Herkunft erfolgreicher sind als einseitig zusammengestellte Belegschaften. Und: Eine Gesellschaft, die z. B. erst viel Geld aus-gibt, um Mädchen und Jungen gleichermaßen zu schulen und später auszubilden, um dann einen großen Teil des Potentials der Mädchen nicht einzusetzen, verbrennt unnötig Ressourcen.
Warum ist nun Künstliche Intelligenz tendenziell diskriminierend?
Grundsätzlich ist richtig, dass künstliche Intelligenz neutral ist. Sie ist nicht per se gegen Frauen, Schwarze oder Alte. Dass sie im Ergebnis dennoch diskriminieren kann, hat zwei Gründe:
Faktor 1: Datenqualität
Erstens ist relevant, WIE eine KI lernt. Sie lernt über Daten. Dabei stützt sie sich auf Muster, die in den Trainingsdaten relevant sind.
Untersuchungen haben z. B. gezeigt, dass eine Computer-Vision Hunde als Wölfe kennzeichnete, sobald sie vor einem verschneiten Hintergrund fotografiert wurden. Denn dann war die Wahrscheinlichkeit höher, dass ein Wolf auf dem Foto abgebildet ist. Auch Kühe wurden als Hunde gekennzeichnet, wenn sie an Stränden standen – denn (fotografierte und im Internet veröffentlichte) Kühe stehen seltener am Strand als Hunde. Sind die Daten biased, ist es automatisch auch die KI, wenn kein Mensch in der Trainingsphase des Algorithmus´ gegensteuert.
Faktor 2: Stellenwert von Diversität im Team
Zweitens ist wichtig, WIE die IT-Teams, die einen Algorithmus trainieren, selbst zusammengesetzt sind.
In Europa und den USA sind diese Teams überwiegend weiß und männlich, was es unwahrscheinlich macht, dass Ergebnisse, die andere Gruppen diskriminieren, in der Entwicklungsphase überhaupt gesucht, geschweige denn gefunden und angegangen werden. Wenn die Menschen, die die KI trainieren, selbst einen „blinden“ Fleck haben, fällt ihnen nicht auf, wenn eine andere Gruppe nicht neutral genug behandelt wird. Wie schnell das geht, konnte man zuletzt bei VW erleben. Dem deutschen und wahrscheinlich hauptsächlich hell-häutigen Marketingteam war nicht aufgefallen, dass ein Werbespot auf dunkelhäutige Menschen diskriminierend wirkte. Jürgen Stackmann, hochrangiger Manager bei VW, stoppte deren Verbreitung.
Unternehmen, die KI entwickeln, sollten deshalb anfangen, formelle Prozesse einzurichten, um diese Art von Fehlern schon bei der Entwicklung dieser Systeme zu testen, zu identifizieren und zu melden.
Aktuell fällt erst auf, dass etwas nicht stimmt, wenn ein Externe, Betroffene sich melden. Aber zu dem Zeitpunkt, zu dem sich jemand beschwert, sind viele bereits unverhältnismäßig stark von der verzerrten Leistung des Modells betroffen – und das Unternehmen selbst in der Kritik, diskriminierend zu sein. Unternehmen, die zugekaufte KI-Lösungen einsetzen, müssen sich und ihre Dienstleister fragen, wie neutral die Ergebnisse sind, statt weiter ethisch grenzwertige Black-Box-Lösungen zu nutzen.
Zusammenfassung: Warum diskriminiert KI?

Autoren:
Prof. Dr. Claudia Bünte
Claudia Bünte ist Professorin für Internationale BWL mit Schwerpunkt Marketing an der SRH Berlin University of Applied Sciences. Hier forscht sie zu Künstlicher Intelligenz in der Wirtschaft. Zuvor war sie in leitenden internationalen Positionen im Marketing u.a. bei Coca-Cola, Beiersdorf, McKinsey und Volkswagen tätig. 2016 gründete sie die Marketingberatung „Kaiserscholle – Center of Marketing Excellence“ in Berlin. Sie berät Top-Manager*innnen in Kernfragen der Markenführung und des Marketings wie z.B. der Implementierung von KI in Marketing-Prozessen. Sie ist Autorin, Keynote-Speakerin und Moderatorin und Vize-Marketingkopf 2020.
Lena Poths
Lena studiert im letzten Semester Wirtschaftspsychologie und steht am Anfang ihrer Karriere. Mit ihrem Wissen aus dem Schwerpunkt Medien, Markt und Kommunikation kann sie klassisches Marketing und Werbepsychologie mit den für Unternehmen immer relevanter werdenden Themen und Fragestellungen der Digitalisierung verknüpfen.
Till Schubert
Till hat sein Studium der BWL mit Schwerpunkt Marketing erfolgreich abgeschlossen. Seit über zwei Jahren forscht und arbeitet er zusammen mit Prof. Dr. Bünte im Bereich der Künst-lichen Intelligenz in der Wirtschaft. Seine Faszination für Zukunftstrends und gesellschaftliche Entwicklungen erhielt er bei einer Management- und Innovationsberatung.
- https://www.amazon.com/Algorithms-Oppression-Search-Engines-Reinforce/dp/1479837245 Noble, S. U. (2018). Algorithms of oppression: How search engines reinforce racism. nyu Press.
- http://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf Buolamwini, J., & Gebru, T. (2018, January). Gender shades: Intersectional accuracy disparities in commercial gender classification. In Conference on fairness, accountability and transparency (pp. 77-91).
- https://www.aaai.org/ocs/index.php/ICWSM/ICWSM15/paper/viewFile/10585/10528 Wagner, C., Garcia, D., Jadidi, M., & Strohmaier, M. (2015, January). It’s a Man’s Wikipedia? Assessing Gender Inequality in an Online Encyclopedia. In ICWSM (pp. 454-463).
- http://papers.nips.cc/paper/6228-man-is-to-computer-programmer-as-woman-is-to-homemaker-debiasing-word-embeddings.pdf rocessing systems (pp. 4349-4357). Bolukbasi, T., Chang, K. W., Zou, J. Y., Saligrama, V., & Kalai, A. T. (2016). Man is to computer programmer as woman is to homemaker? debiasing word embeddings. In Advances in neural information processing systems (pp. 4349-4357).
- https://iug.htw-berlin.de/?page_id=473; Folkerts, Schreck, Riazy, Simbeck: Analyzing Sentiments of German Job References (2019)




