
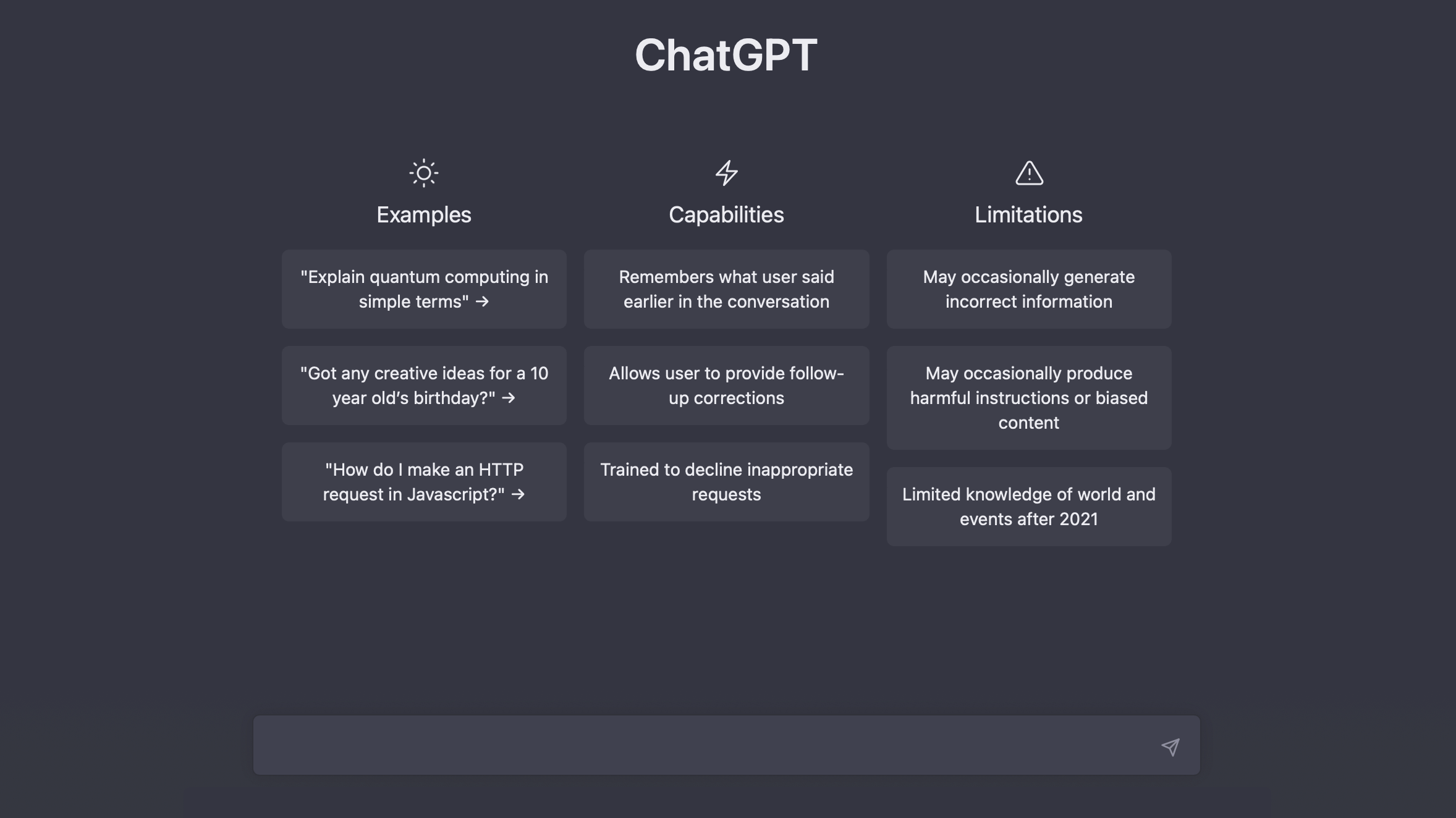
Was ist Chat GPT?
GPT steht für „Generative Pretrained Transformer“. Ein Chat GPT ist ein KI-basiertes Textgerierungsprogramm. „Generative“ bezieht sich auf die Fähigkeit des Modells, neue Texte zu generieren, „Pretrained“ bezieht sich auf den Vor-Trainingsprozess, bei dem das Modell an einer großen Menge an Textdaten ausgebildet wurde, bevor es für eine spezifische Aufgabe eingesetzt wird, und „Transformer“ ist die Art der Architektur, die verwendet wurde, um das Modell zu implementieren. Kurz gesagt, GPT steht für ein vortrainiertes Modell, das in der Lage ist, Texte zu generieren, basierend auf einer Transformer-Architektur.
Das Modell wurde an einer großen Menge an Texten im Internet ausgebildet, um auf Fragen und Aufforderungen in natürlicher Sprache zu antworten. ChatGPT kann in einer Vielzahl von Anwendungen eingesetzt werden, wie z.B. im Kundensupport, in Chatbots oder in personalisierten Empfehlungen.
Was unterscheidet Chat GPT von anderen, bisherigen KI-basierten Modellen?
Die meisten KI-Systeme sind heute sogenannte Klassifikatoren, was bedeutet, dass sie z.B. darauf trainiert werden können, zwischen Bildern von Hunden und Katzen zu unterscheiden, oder gesunde Körperzellen von Krebszellen zu unterscheiden. Generative KI-Systeme dagegen können darauf trainiert werden, ein Bild eines Hundes oder einer Katze zu erzeugen, das in der realen Welt nicht existiert. Die Fähigkeit der Technologie, kreativ zu sein, ist der entscheidende Unterschied.
Generative KI ermöglicht es Systemen, hochwertige Artefakte wie Videos, Erzählungen, Trainingsdaten und sogar Designs und Schaltpläne zu erstellen. Textanwendungen finden sich bei Chat GPT von Open AI, digitale Bildgeneratoren wie DALL·E 2, Stable Diffusion und Midjourney können Bilder aus Text erzeugen.
Welche Technik steckt hinter generativen KIs:
Es gibt eine Reihe von KI-Techniken, die für generative KIs eingesetzt werden, aber in letzter Zeit haben sogenannte „Foundation Models“, also Grundlagenmodelle das Rampenlicht erobert. Diese Basismodelle werden anhand allgemeiner Datenquellen auf selbstüberwachende Weise trainiert und können dann zur Lösung neuer Probleme angepasst werden. Basismodelle basieren hauptsächlich auf Transformer-Architekturen. Transformer-Architekturen lernen den Kontext und damit die Bedeutung, indem sie Beziehungen in sequenziellen Daten verfolgen. Transformer-Modelle wenden eine sich weiterentwickelnde Reihe mathematischer Techniken an, die als Aufmerksamkeit oder Selbstaufmerksamkeit bezeichnet werden, um subtile Wege zu erkennen, wie sich selbst weit entfernte Datenelemente in einer Reihe einander beeinflussen und voneinander abhängen.




